虚拟机在执行GC垃圾回收操作时所有线程(包括UI线程)都需要暂停,当GC垃圾回收完成之后所有线程才能够继续执行(这个细节下面小节会有详细介绍)。也就是说当在16ms内进行渲染等操作时如果刚好遇上大量GC操作则会导致渲染时间明显不足,也就从而导致了丢帧卡顿问题
android的性能优化主要从下面4个方面入手
UI性能问题优化
UI卡顿常见原因
- 在UI线程中做轻微耗时操作,导致UI线程卡顿
- 布局太过复杂,layout嵌套太多,无法在16ms内完成渲染
- 同一时间执行动画次数过多,导致CPU、GPU负载过重
- View过度绘制,使某些像素在同一时间被多次绘制,导致CPU、GPU负载过重
- View频繁出发onMeasure、onLayout,致使累计耗时过长及整个View频繁的重新绘制
- 内存频繁出发GC过多(同一帧中频繁创建内存)导致暂时阻塞渲染操作
- 冗余资源导致加载和执行过慢
Layout层级分析
UI层级分析工具hierarchy view 分析layout视图情况,以及调试自定义view时及时观察measure layout draw的运行时间
GPU的过度绘制,在开发中选项中开启过渡绘制显示,可根据app界面的颜色显示查看是否过度绘制并优化
| 颜色 | 含义 |
|---|---|
| 无色 | WebView等的渲染区域 |
| 蓝色 | 1x过度绘制 |
| 绿色 | 2x过度绘制 |
| 淡红色 | 3x过度绘制 |
| 红色 | 4x(+)过度绘制 |
譬如:优化布局层次机构,减少没必要的背景。暂时不显示的View 设置为gone而不是invisible
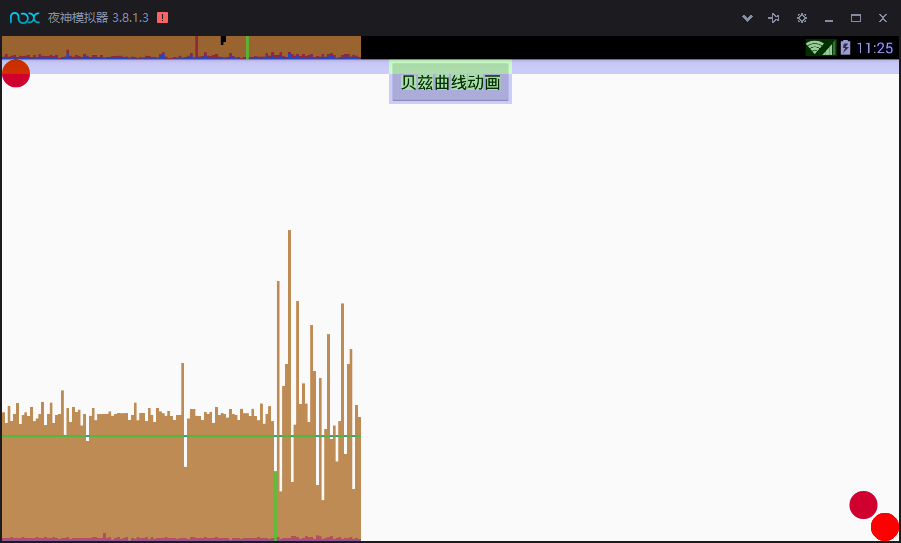
每个柱状图偏上都有一根代表16ms基准的绿色横线,每一条竖着的柱状线都包含三部分(蓝色代表测量绘制Display List的时间,红色代表OpenGL渲染Display List所需要的时间,黄色代表CPU等待GPU处理的时间),只要我们每一帧的总时间低于基准线就不会发生UI卡顿问题(个别超出基准线其实也不算啥问题的)。
这个工具只能看出是否丢帧,却不能分析丢帧原因,所以需要配合traceview和systrace来进行原因追踪
Lint进行资源及冗余UI布局等优化
gc导致的性能分析(memory检测、gc日志输出、Allocation Tracker工具进行配合定位分析问题):
gc频繁执行的原因:
- 短时间内大量频繁的对象创建和释放操作(内存抖动现象)
- 短时间内已经存在大量的内存占用介于阈值边缘,当创建对象导致超越阈值时候触发gc操作
触发gc的主要原因:
- 内存分配失败
- 但分配的对象大小超过限定阈值(根据系统而定具体值)
- 对gc的显式调用(System.gc())
- 外部内存分配失败
从内存角度优化其中就是要避免gc的频繁执行造成UI视觉的卡顿:
- 检查代码是否有频繁触发的代码中存在大量内存分配
- 尽量避免在对此for循环中频繁分配内存
- 避免在自定义view中的ondraw方法中进行复杂的朝族及对象创建,比如paint的实例化不要写在ondraw中
- 对于并发下载应该避免多次创建线程对象,而应该用线程池的方式处理
分析完原因之后可配合Allocation Tracker工具进行gc导致的性能问题定位分析
Android studio Monitor面板的memory的tracview记录了应用程序每个函数执行的时间,以此来进行性能分析
ANR导致UI卡顿:
常见ANR的原因
- 按键触摸事件派发超时,一般阈值为5s
- 广播阻塞ANR,一般阈值为10s
- 服务超时ANR,一般阈值为20s
发生ANR时可在/data/anr/traces.txt文件中查看分析原因
Memory内存性能优化
内存泄露性能分析
内存泄露产生原因:
在某些对象的生命周期执行完的时候,该对象本来应该被垃圾回收,但此时这个对象还被别的对象持有引用,那么就会导致内存泄露
代码举例分析:
上面例子中,在当前Acvitivy执行完onDestroy()后,这个Activity的应用被单例模式的DbManager对象持有,就无法得到垃圾回收,也就造成了内存泄露
内存泄露检测方式或工具:
| 查看方式 | 场景 |
|---|---|
| AS的Memory窗口 | 平时用来直观了解自己应用的全局内存情况,大的泄露才能有感知。 |
| DDMS-Heap内存监测工具 | 同上,大的泄露才能有感知。 |
| dumpsys meminfo命令 | 常用方式,可以很直观的察觉一些泄露,但不全面且常规足够用。 |
| leakcanary神器 | 比较强大,可以感知泄露且定位泄露;实质是MAT原理,只是更加自动化了,当现有代码量已经庞大成型,且无法很快察觉掌控全局代码时极力推荐;或者是偶现泄露的情况下极力推荐。 |
内存泄露导致的常见的问题:
- 应用卡顿,响应速度满(内存占用高,JVM会频繁触发GC)
- 后台进程被转化为空进程,从而被系统kill(内存超过阈值)
- 崩溃(超过内存阈值)
开发中应该如何规避内存泄露的几点建议:
- 不要对一个activity context保持长生命周期的引用
- 非静态内部类的静态实例容易造成内存泄露,尽量使用静态类和弱应用来处理
- 对象的注册和反注册没有成对出现,比如广播接收器、后台服务、观察者的注册和反注册
- 创建与关闭没有成对出现,比如Cursor资源必须手动关闭,WebView必须手动销毁,流等对象用完后必须手动关闭
- 不要在执行频率很高的方法或循环中创建对象,可创建对象容易做缓存处理
内存溢出OOM性能分析
内存泄露和内存溢出的关系是,但内存泄露超过一定阈值后就会造成内存溢出
造成内存溢出的原因:
- 内存泄露,长时间累计无法释放导致oom
- 程序短时间内大量消耗内存(比如加载未处理的超大高清巨图)导致超过阈值,致使oom
从上面不难得出导致内存溢出的直接原因就是内存占用超过阈值
开发中规避内存溢出的建议:
- 不要直接加载高清大图,可用BitmapFactory.option设置图片属性,或者第三方图片框架加载,fresco glide
- 有些地方避免使用强引用,替换为弱应用
- 对需要批量处理的数据进行缓存处理,或者事务处理(数据多次加载,一次性提交,提升系统性能)
- 尽可能复用资源,比如字符串、颜色、尺寸、动画、布局等资源复用
- 尽量使用线程池代替多线程操作,节约内存和CPU占用
- 多用try catch进行异常处理,避免不必要的闪退
- 尽量优化代码逻辑,减少冗余,编译打包时进行优化对齐处理
API使用、代码编写性能分析
字符串的拼接 +、StringBuffer(线程安全)、StringBuilder的选择
HashMap、ArrayMap、SparseMap的使用选择
HashMap 内部使用默认容量的数组存储数据,每个元素存放一个链表头节点,其内部结构为链表结构,因为元素查询采用遍历法,所以在查询元素时效率低,成本高
SparseMap 内部避免了对key进行自动装箱,采用两个数组来存储数据,一个存储key,一个存储value,内部数据采用压缩方式,从而节约内存空间,元素查询采用二分法,所以性能比hashmap高,比hashmap省内存
ArrayMap内部使用两个数组进行数据存储,一个记录Key的Hash值,一个记录Value值,它和SparseArray类似,也会在查找时对Key采用二分法。
当数据量不大(千位级内)且Key为int类型时使用SparseArray替换HashMap效率高;当数据量不大(千位级内)且数据类型为Map类型时使用ArrayMap替换HashMap效率高;其他情况下HashMap效率相对高于二者
使用ContentProviderOperation避免多次调用ContentProvider
所有的操作都在一个事务中执行,可以保证数据的完整性。
批量操作在一个事务中执行,所以只用打开、关闭一个事务。
减轻应用程序与ContentProvider间的多次频繁交互,提升性能
其他代码编写性能优化的建议
- 避免使用枚举,编译后不但占空间,而且加载也费时
- Handler发送消息时尽量用obtain去获取已经存在的message进行复用,而不是每次使用都用创建新的message对象,减轻内存压力
- 尽量不要用getXXX、setXXX对机制的内部成员进行操作,直接使用,提高代码执行效率,也可避免65536问题
- 不要一味的为了设计模式去抽象代码,代码抽象系数和代码执行时间成正比
Android应用电池耗电性能分析
常见耗电量大的原因:
- 网络数据交互
- GPS定位
- 大量内存性能问题
- 冗余的后台线程和服务
针对上面的原因提出相应的对策:
- 网络操作之前进行网络状态判断
- 数据传输中使用高效的数据交互方式,比如json
- 对定位要求不高的的场景使用网络定位,而不是GPS定位
- 减少网络请求次数和请求时间间隔
- 后台任务要尽可能少的唤醒CPU